
Predicting Movie Gross Revenue
Can you predict the success or more so, the total gross of a movie at the box office? What ensures the financial success of a movie? Is it the genre, or is it the star power of a certain actor? I tried to answer some of these questions by tinkering around with data from boxofficemojo.com.
For this analysis, I scraped 10 years of movie data from boxofficemojo using Pythons’s Beautiful Soup and Selenium libraries. Collected the movie details from the respective movie page.
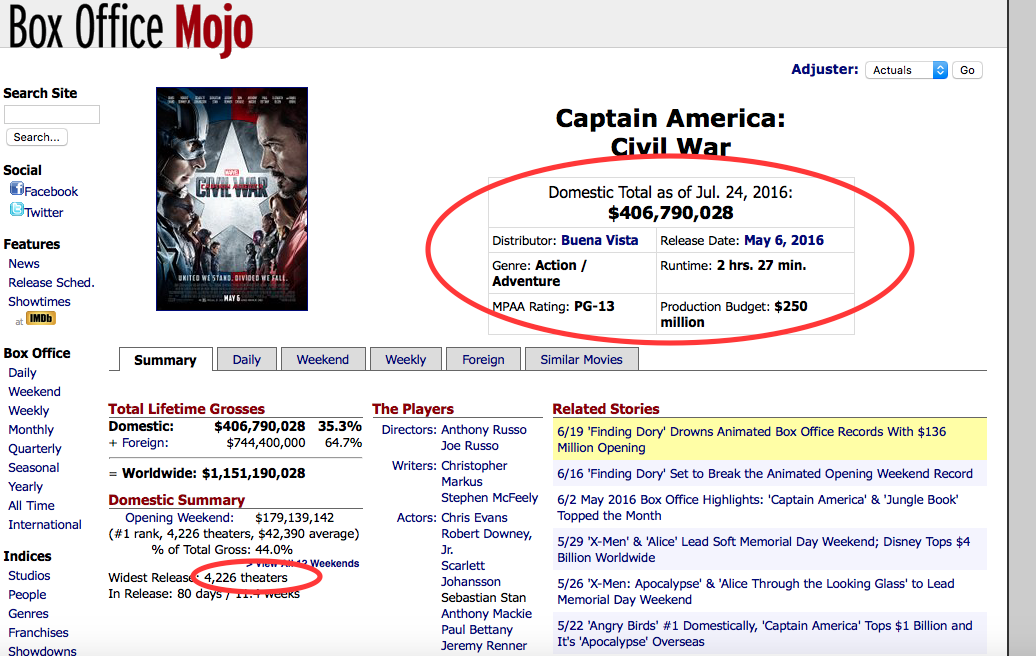
The actor/director/writer/producer’s information was collected from their respective pages.
Apart from the readily available variables, I added a few computed ones. I calculated the average gross of previous movies of the people(Actors,director,producer,writer) involved in a specific movie.
After some more data munging,I went ahead and built a linear regression model on the following features:
Genre
Run Time
MPAA - Rating
Budget
Number of screens
Number of movies
Previous average gross of the following:
Three primary actors
Director
Producer
Writer
Actors*Director
Actors*Actors
Genre*Month
Rating*Month
Rating*Genre
‘*’ indicates interaction
Prima facie the model looked good. Too good to be true! I had an R-squared of around 0.83 ! And, my coefficients were of the order e+07 making the model too sensitive to changes. Did I overfit my data?
I divided the model into train and test data and ran the model on the data. The R-squared dropped to 0.63. I surely did overfit my model.
I went on to check if I have some more problems with the data and the model, in general. The following results caught my eye: Prob(Omnibus): 0.000 Prob(JB): 0.00 The p-value is less than 0.05, rejecting the null hypothesis of having a normally distributed data.
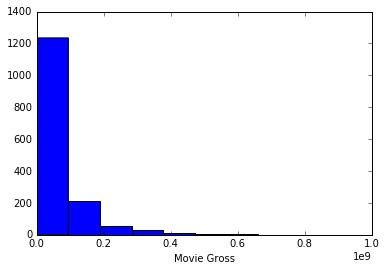
The response variable, Gross revenue is clearly right skewed.
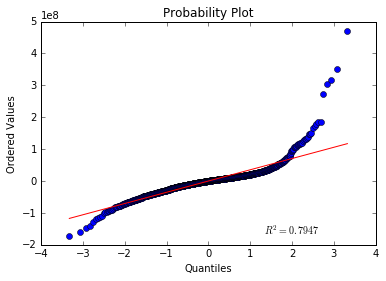
The Q-Q plot is not a straight line indicating that the error terms are not following a normal distribution.
I have some options to care of this. I can either collect more data, so that the data follows normal distribution by central limit theorem or I can try to transform the data so that it follows a normal distribution. I chose to apply a logarithmic transformation.
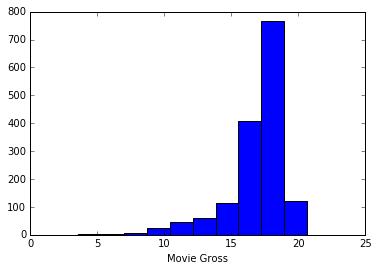
Having taken care of the non-normal distribution, I have one more problem on my hand - Overfitting ! Regularization seems to be a plausible solution. So, Lasso or Ridge it is ! I further divided my data - Train data, validation data and test data.
Model formulation:
At each iteration I reduced the number of model parameters by taking out variables that are not significant, and it improves the model performance both on the training set and test set. After multiple iterations and cross validations, I came up with a model that seem to be consistent with the train and test data.
Results :
Method : Ridge Regression with 10-fold cross validation
R-square on test data : 0.78
Mean -squared error : 0.9758
Method : Lasso Regression with 10-fold cross validation
R-square on test data : 0.78
Mean -squared error : 0.9755
Both the models seems to have similar results. I went ahead with Lasso, as i want to get rid of less significant variables.
Features that positively affect Gross Revenue are :
Number of screens
Budget
Director
Run Time
Months : December,
May - July, November
Genre : Drama, Romance
Rating : R - Rated
Rating * Months : PG - May to July
: R - December
Actors
Features that negatively affect Gross Revenue are :
Rating : Unrated
Months : Jan -April
Rating * Months : R - May to July
The influence of number of screens is kind of obvious given that the more the number of screens, the more chances for good collections. Movies perform well in December given that it is a holiday. It is interesting to see that May-July is also favorable. One possible hypothesis is whether school is in session and that could be tested more strictly in the future . This is later reinforced by the significance of interaction of PG-May to July. One more interesting and a rather, surprising result is that the presence of an actor whose previous movies have done well does not affect the revenue much. This is not the case with the director. May be content is the king, afterall!
So, how well did the model perform on the test data?

Got 20 out of 25 right. Not so bad !